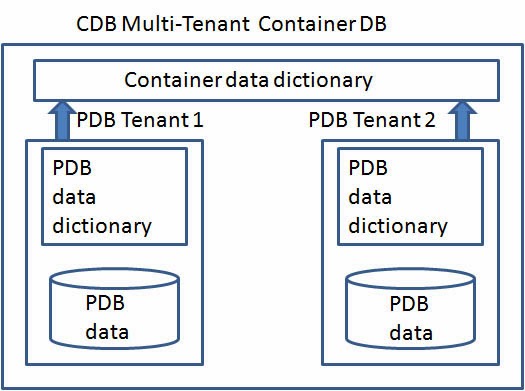
In the next post (Part Three) I'll talk about how to access the sample schemas, which, as of 12c, are now tucked away inside "pluggable" databases.
1. Install Java (specifically JDK 7u45 & NetBeans 7.4, or something more or less equivalent). The download can be found here: http://www.oracle.com/technetwork/java/javase/downloads/index.html. Follow the installation instructions found here: http://www.oracle.com/technetwork/java/javase/downloads/jdk-7-netbeans-install-433844.html#linux
2. Download SQL Developer 4 rpm file. The download is here: http://www.oracle.com/technetwork/developer-tools/sql-developer/downloads/sqldev-download-v4-1925679.html
3. Install SQL Developer following the instructions found here: http://www.oracle.com/technetwork/developer-tools/sql-developer/downloads/sqldev-install-linux-1969676.html
4. During the installation you should probably accept all the defaults, at least as far as where things are to be installed (/usr/local/). If you get a "DISPLAY" error at this point (or at any other point) refer to step #5 in the previous post.
5. Once the installation completes, log in as the oracle user and just execute "sqldeveloper". The first time you fire up SQL Developer it will ask you where your JDK is, and you should enter something like this: /usr/local/jdk1.7.0_45.
6. That's it! I really should be that simple. As long as you know your way around Linux, and you have installed Oracle properly in the first place, there should be no problems. But if you do run into any problems feel free to leave a comment and I will see if I can help you out!